Vorweg: ich fühle mich Heute nicht sehr gut, könnte sein dass ich Fieber habe. Da kommt man auf die merkwürdigsten Ideen… 

openDB
Vor mir liegt also eine MySQL-Datenbank in der viele Filme, deren IMDB-Bewertungen und die mitwirkenden Schauspieler gelistet sind. Und mein vollgeschnoddertes Gehirn stellt mir die Frage: welcher Schauspieler hat wohl in den bestbewerteten Filmen mitgewirkt?
Die Struktur der Datenbank ist nicht unbedingt ideal für so eine Abfrage, daher hat es fast eine halbe Stunde gedauert bis ich dieses kleine Monster hatte („Ein Kerlchen von erlesener Hässlichkeit“ hätte meine Mathelehrerin wohl dazu gesagt. ):
select count(1) filme, round(avg(ia1.attribute_val),2) durchschnitt, ia2.attribute_val schauspieler
from item_attribute ia1
join item_attribute ia2 on ia1.item_id=ia2.item_id
join item i on i.id=ia1.item_id
join item_instance ii on ia1.item_id=ii.item_id
where ia1.s_attribute_type='IMDBRATING'
and ia2.s_attribute_type='ACTORS'
group by ia2.attribute_val
having filme>=10
order by durchschnitt desc
limit 30;
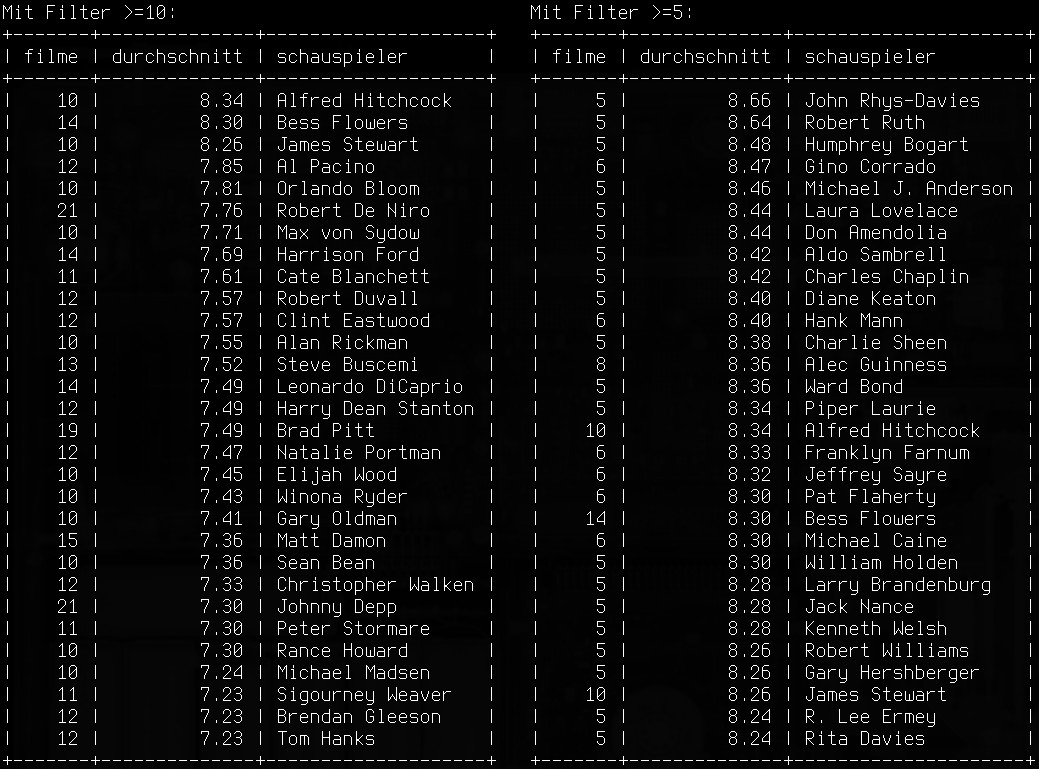
Die besten, der besten…
Das Ergebnis mit beiden Filtern ist im nebenstehenden Screenshot zu sehen. Man bedenke: Datenbasis sind ausschließlich die Filme die ich original hier habe (ja, da sind wirklich keine Kopien dabei!). Und bewertet wurde nicht die Leistung der Personen, sondern die der Filme in denen sie gespielt haben. Ich muss beispielsweise gestehen dass mir John Rhys-Davies erstmal nichts gesagt hat. Es reicht aber, dass er in zwei Indiana-Jones- und drei Herr-der-Ringe-Filmen mitgespielt hat (als Sallah bzw. Gimli), damit er die eine Liste anführt. Alfred Hitchcock war ein großartiger Regisseur, durch seine kleinen Cameo-Auftritte steht er aber auch als Schauspieler an der Spitze der Liste.
Apropos Regisseur: wenn ich nicht nach Schauspielern sondern nach Regisseuren auswerte — vielleicht ist das fairer — führt bei einem Filter von 5 Sergio Leone die Liste an, gefolgt von Akira Kurosawa und Charlie Chaplin.
Oh, und wo ich gerade dabei bin… hier nochmal eine Liste der Schauspieler von denen ich die meisten Filme habe. War dann nur noch eine Fingerübung:
Bruce Willis (38), Samuel L. Jackson (24), Robert De Niro (21), Tom Cruise (21), Johnny Depp (21), Brad Pitt (19), Morgan Freeman (16), Harvey Keitel (15), Nicole Kidman (15), Matt Damon (15), Leonardo DiCaprio (14), Harrison Ford (14), Mel Gibson (14), Bess Flowers (14), Steve Buscemi (13).
Die Reihenfolge gibt komischerweise meine persönliche Meinung von deren Können überhaupt nicht wieder… Robert De Niro, Al Pacino oder auch Sean Connery halte ich für deutlich fähiger als Bruce Willis, dabei sind die letzten beiden nicht mal in der Top15…
Naja, vielleicht sagt das ja doch alles nichts aus. Vielleicht sollte ich mir mal die Datenbasis der IMDB besorgen (ja, das geht.) und darauf Auswertungen fahren. Nicht nur auf mein eigenes Regal. Zumindest hat es mir geholfen, eine Weile nicht nur über die Schnodderei nachzudenken…